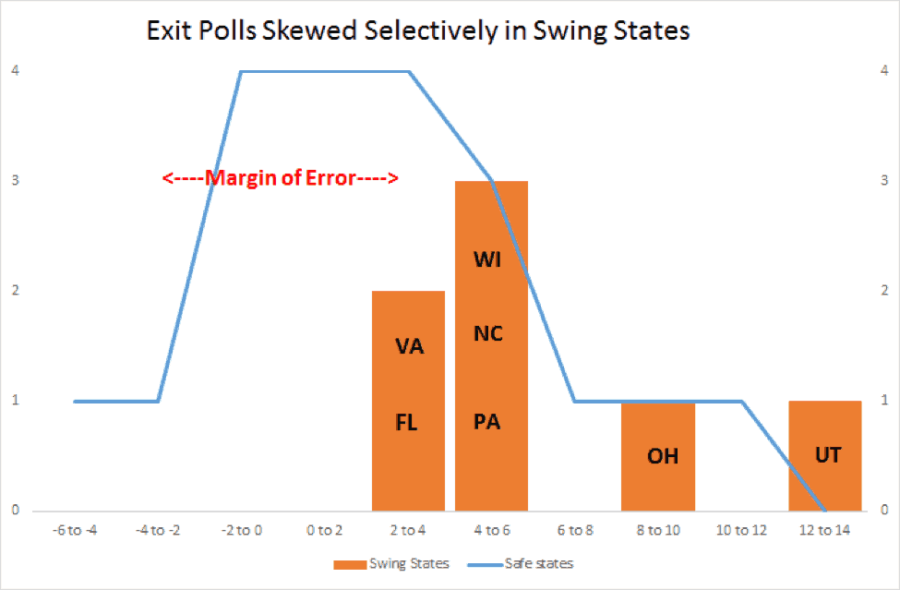
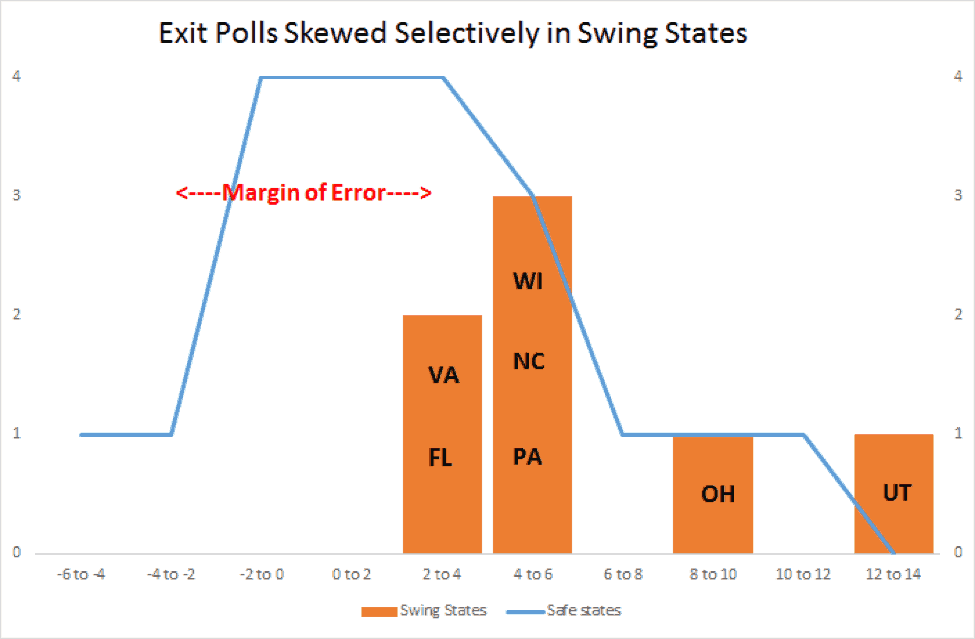
By Josh Mitteldorf, Ph.D.
Are votes in American elections being counted fairly and accurately? In an open democracy worthy of the name, this should not be a question for forensic science, but in 21st Century America, that’s just what it is. America is unique in the developed world in counting votes with proprietary software that has been ruled a trade secret, not open to inspection, even by local officials whose responsibility it is to administer elections. As we have learned last week, there is stiff resistance to looking at the ballots with human eyes which might offer a check on the computers. So we are left looking at statistics and anecdotes, trying to determine whether vote counts are honest and reliable. The evidence does not inspire confidence. But whatever you think of the evidence, there is no justification for a system without the possibility of public verification. If you missed it, read Part 1: Background
Part 2: Computerized Vote Theft–A Taboo Topic
Yesterday I listed some well-known ways in which the vote can be skewed: Suppression, gerrymandering, the electoral college, voter intimidation and the purging of voter lists. Compounding this is a media tendency to under-report, or sideline as fringe, some genuinely popular ideas such as universal health care and scaling back military spending.
All the above forces push electoral politics away from the people’s concerns, toward a corporate agenda. And yet, could it be that even all this distortion is not enough to explain the state of American politics? Is there direct, computerized vote theft occurring to push corporate dominance over the top? Evidence for this possibility comes from three sources.
Vulnerability: Push-button and touch-screen voting systems are easily misprogrammed, and detection is all but impossible. The optical readers that count paper ballots are just as easily corrupted, and they are better only if there is an independent hand count keeping them honest.
Statistics: Polls often diverge from reported vote counts, with the vote counts far more often favoring the candidate on the political Right. In some cases, studies have revealed patterns in the discrepancies that suggest it is the reported vote counts that are at fault.
Anecdotes: There are examples in which first-hand stories have come out, with evidence from whistle blowers and data leaks. These will be explored in parts 3 & 4 of this series.
1. Vulnerability
Computer scientists who look at security of computerized voting find the systems laughably vulnerable to both error and mischief. Even the common practices that are used to encrypt our emails and protect our Amazon accounts with passwords are not consistently followed in the world of voting machines. Here is an article from Wired on voting machine security. Here is a 2008 New York Times Magazine article with stories of voting machine failures. Here is an in-depth study of one common voting machine, from the Princeton Computer Scientist Ariel Feldman. A UCSD analysis of a similar system concludes, “that this voting system is far below even the most minimal security standards applicable in other contexts.” Politico in August explored what it would take to hack a presidential election and came up with a depressing but not surprising conclusion: Not much. Last year, Virginia de-certified 3,000 voting machines that had been used throughout the state for 12 years, a welcome beginning.
Here is a report from the NYU Brennan Center for Justice, fully documented and replete with sensible recommendations for a comprehensive reform of the American system of voting.
Previous
Be sure to read parts 3 & 4 at Op-Ed News:
- Part 3: http://opednews.com/articles/
Stories-of-Election-Theft-by- Josh-Mitteldorf-Election- Integrity_Election-Integrity- 161222-115.html - Part 4: http://www.opednews.com/
articles/Election-Theft-2016- Part-by-Josh-Mitteldorf- Election-Integrity_Election- Integrity-161223-660.html
All these sources document vulnerability to outside hacking. Just as significant is the possibility of an inside job. A few companies with shifting ownership control the machines that count most of the votes in America. Diebold, the most famous, changed the product line name to Premier, and then sold the division to ES&S, the largest voting machine company.
Election Day is now dominated by a handful of secretive corporations with interlocking ownership, strong partisan ties to the far right, and executives who revolve among them like beans in a shell game…
…As it happens, many of the key staffers behind our major voting-machine companies have been accused or convicted of a dizzying array of white-collar crimes, including conspiracy, bribery, bid rigging, computer fraud, tax fraud, stock fraud, mail fraud, extortion, and drug trafficking.
Computerized counting of votes is based on software, and typically a state or local election does not have the source code, so they must try to validate the code by “black box testing,” where all they know is the input and the output. They rarely have resources to do an adequate job, and (in my opinion) it would not be difficult to write the software in such a way that it detects the difference between a test and a real election, and performs differently in the two situations. The only place I know of where open-source software is used to count votes in Humboldt County, CA.
Push-button and touch-screen paperless machines are clearly the most difficult to verify; but there are problems with optical scan machines as well. Op-scan systems are programmed to “read” a paper ballot and record the votes that are registered on set locations. The advantage they offer over paperless systems is that the votes can be counted in parallel by hand. This can be in an (unannounced) random sample of precincts, as a statistical spot check; or it can be a full hand re-count in case doubts arise about the accuracy of the numbers reported by machines. In practice, random spot checks are the exception, not the rule, and there are stiff barriers to full recounts almost everywhere in America. Under these circumstances, op-scan machines can be just as vulnerable as paperless machines.
For example: The op-scan machines must be programmed to look at a particular location on the paper for a check mark or filled-in square corresponding to each candidate.
| ◻ Benedict Arnold ◼ George Washington |
The computer-reader might be programmed with just the right location for the Benedict Arnold box, but the location of the George Washington box is offset by a few mm. 100% of votes for Benedict Arnold will register, and 98% of marks in the space for George Washington will have enough overlap that they register as well. But in the aggregate, 2% of ballots for George Washington will be reported as “undervotes” — no candidate was chosen. This kind of misreading will rarely be caught in a “black box” test, and in the unlikely event that it is detected, it looks like an innocent “miscalibration”.
This year, large counts of undervotes in Michigan suggest this as a possible explanation.
2. Statistics
 Exit polls are the best independent check that we have. Broadcast and internet news media contract with companies to ask voters who they voted for in a specially selected set of sample precincts that mirror the demographics of the entire state. Exit polling is a mature, sophisticated science, routinely used for international verification of elections in Europe and Latin America. But in America, polling companies use exit polls not to check up on the validity of the reported results but to predict them on election night. So exit poll methodology is calibrated by learning from “mistakes” in previous elections. This means that any systematic corruption of the election machinery eventually corrupts the exit poll as well. A more immediate problem: Exit poll raw numbers are never* reported to the public, and are blended with officially-reported results during the course of the night after an election, so that the news sources can offer their best prediction of the outcome.
Exit polls are the best independent check that we have. Broadcast and internet news media contract with companies to ask voters who they voted for in a specially selected set of sample precincts that mirror the demographics of the entire state. Exit polling is a mature, sophisticated science, routinely used for international verification of elections in Europe and Latin America. But in America, polling companies use exit polls not to check up on the validity of the reported results but to predict them on election night. So exit poll methodology is calibrated by learning from “mistakes” in previous elections. This means that any systematic corruption of the election machinery eventually corrupts the exit poll as well. A more immediate problem: Exit poll raw numbers are never* reported to the public, and are blended with officially-reported results during the course of the night after an election, so that the news sources can offer their best prediction of the outcome.
For example, the results that are displayed right after the polls close may be based completely on exit polls; but two hours later when 2/3 of the precincts have reported their numbers, the same display on the same web site will contain different numbers, consisting of a weighted average of exit polls and reported results that reflects the best projection that polling scientists are able to make with that available information. They are still reported as “exit polls,” but the numbers hardly represent an independent check. And by morning of the following day, the reported “exit poll” numbers are actually dominated by the official results, supporting the illusion that there is good agreement between the polls and the official results.
Statisticians and citizen activists in the election integrity movement have learned to catch screen shots of exit polls announced the moment that polls close, minimizing the opportunity for adumbration. But the truth is that we never know what we are getting, and polling companies consistently decline our requests for raw numbers or accounts of their methodology.
There is also an inherent problem in exit polls: Participation in exit polls is, of course, voluntary, and “response bias” is the name given to the phenomenon that Republicans might be more likely to say “yes” to the poll than Democrats, or vice versa. I have personally planned and analyzed two independent exit polling projects (in 2006 and 2016), and I can testify that this is a very real problem, that it can run in either direction, and that it is difficult to predict or to control for.
So the question for the statisticians: When exit poll results differ significantly from the reported election results, how can we know if we are looking at a corrupted election or at response bias?
Answer: Wherever we can, we try to do controlled experiments, comparing performance of the same poll in two places or two races on the same ballot, in circumstances where we are confident that one of the two is unlikely to be stolen, and so can be referenced as a control.
Ingenuity is the soul of this art. My favorite example is a self-funded, independent poll of the 2006, commissioned and funded by Election Defense Alliance, for which I was an analyst. [Fingerprints of Election Theft] This was not an exit poll but a telephone poll. The total response rate for such polls is typically between 1 and 4% (even in those days before robo-calling was quite so ubiquitous). Response bias might be expected to be an insurmountable problem. To control for this, we compared hotly-contested races with races where a wide margin was expected. Our premise was that if a race is expected to be a lopsided victory for one side or the other, then the perpetrators would not be motivated to try to steal it. It is races that are projected to be tight (within 10%) that provide plausible targets. EDA’s Jonathan Simon who searched the country for Congressional Districts where there was at least one competitive and one non-competitive race on the same ballot. For example, there might be a Congressman with long tenure who was widely expected to prevail, but a Governor’s race with no incumbent and a tight race between a Democrat and a Republican. Because we had the raw data, we were able to perform a sensitive pair analysis, using the responses for a contested and an uncontested race on the same ballot, using answers from the same respondents. It worked, and we were able to get excellent statistics from lousy data. The uncontested races agreed well with our telephone poll, but the contested races showed a consistent bias (p<0.007), favoring Republicans.
Using exit polls from news pages on election night, we do not have access to the raw data, and finding appropriate controls is yet more difficult. Comparison is necessarily less direct. We have compared contested and uncontested elections in Congressional races across the country; we have compared Republican primaries to Democratic primaries held at the same site, same day; we have compared exit poll results from regions that use hand-counted and computer-counted votes. Each election presents its unique challenges. We have often found statistical cause for suspicion. Typically, the aggregate exit poll discrepancies are significant at a level of many standard deviations, probabilities astronomically small. But when we limit analysis to cases where we have a clear test-control pair, the argument becomes technical, and it’s rarely an eye-popping result that we can explain to the public, or to an election official.
_______________
* Never? Well, hardly ever. On the night of the 2004 general election, there was a computer glitch that prevented the National Exit Poll from diluting their poll numbers with the official returns as they came in. As a result, the disparity between exit polls and official counts appeared starkly for the public to see. Two months later, NEP responded to public questions with a white paper on their methodology. Working with election integrity advocates across the country, I drafted a response to their response, interpreting evidence within their white paper as suggestive of election theft.
Previous
Be sure to read parts 3 & 4 at Op-Ed News:
- Part 3: http://opednews.com/articles/
Stories-of-Election-Theft-by- Josh-Mitteldorf-Election- Integrity_Election-Integrity- 161222-115.html - Part 4: http://www.opednews.com/
articles/Election-Theft-2016- Part-by-Josh-Mitteldorf- Election-Integrity_Election- Integrity-161223-660.html