Skip to content
Menu
Featured Blogs
EU Horizon Blog
ESA Tracker
Experimental Frontiers
Josh Mitteldorf’s Aging Matters
Dr. Lu Zhang’s Gondwanaland
NeuroEdge
NIAAA
SciChi
The Poetry of Science
Wild Science
Topics
Brain & Behavior
Earth, Energy & Environment
Health
Life & Non-humans
Physics & Mathematics
Social Sciences
Space
Technology
Our Substack
Follow Us!
Bluesky
Threads
FaceBook
Google News
Twitter/X
Contribute/Contact
A Big Bang Inside a Dying Star Could Stop Black Holes from Ever Forming
A Graveyard of 10 Million Whales Has Been Found Nearly Seven Kilometers Down
The Kids Are All Right: Zoo Ponies Stay Calm Under Petting Yet Bolt at an Excavator
To Find New Physics, an AI First Has to Forget the Old Physics It Learned
An Unmanned Rooftop Machine Runs All Day on Sunlight and Air
Almost Everyone Drifts Counterclockwise When They Walk, and Nobody Knows Why
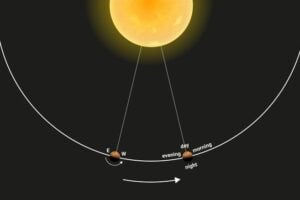
A Planet So Hot Its Water Falls Apart Has Different Weather at Dawn and Dusk
Two-Week Brain Tumor Test, Done in Twelve Minutes
Headset Lets Beginners Read an Ultrasound Like Veterans
One in Four Young Canadians Now Carries the Mark of Social Anxiety
A Pinch of Scandium Keeps Carbon Nanotube Forests Growing Where Iron Alone Burns Out
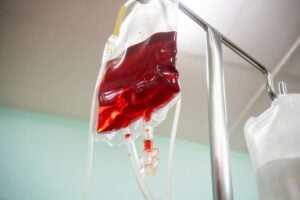
Drug Costing Less Than $10 Could Spare Millions of Surgery Patients a Blood Transfusion
Ten-Kilo Telescope Built Like a Crab’s Eye Could Finally Map the Whole Moon’s Chemistry
Eating Your Five-a-Day Won’t Get You the Compound Your Heart Wants Most
Older posts
Page
1
Page
2
…
Page
5,964
Next
→