Key Takeaways
- The current academic publishing system lags behind AI advancements, creating a risk for patient safety in medicine.
- AI generates tools faster than peer-reviewed evidence can validate, often running 12-18 months behind.
- Traditional articles are opaque, separating claims from data, which affects the trustworthiness of AI models relying on unverifiable research.
- A shift to dynamic research objects could link claims directly to data and analysis, enhancing verification and transparency.
- Institutional resistance poses a significant barrier to reforming the publishing system despite the pressing need for change.
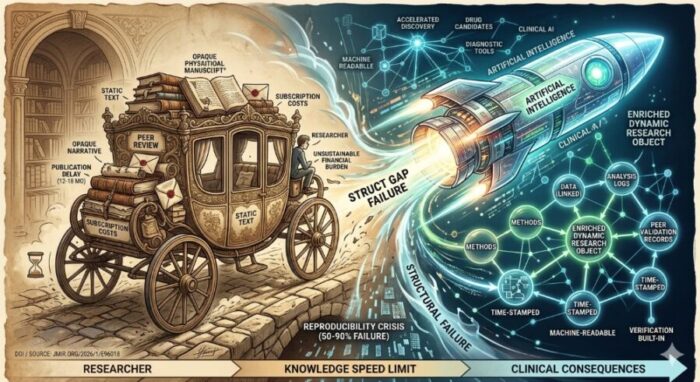
Knowledge, it turns out, has a speed limit. Not the speed at which we can generate it or even analyse it, but the speed at which we are permitted, institutionally, to trust it. That limit was set sometime in the seventeenth century, when the first academic journals began circulating among natural philosophers, and it has barely shifted since. The machinery around it has changed, obviously. The manuscripts are digital. The reviewers get emails instead of letters. But the essential structure, a static text artifact submitted, assessed in private, and released months or years later, remains almost intact. And for most of science’s history, that was probably fine.
It is no longer fine. The gap between what artificial intelligence can now discover and what the publishing system can formally validate has become, in the estimation of at least some researchers, a genuine threat to medicine and public health, not merely an academic inconvenience.
The argument is laid out in a new commentary in the Journal of Medical Internet Research by Boon-How Chew, a physician and professor of family medicine at Universiti Putra Malaysia who studies the intersection of AI innovation and scientific communication. His central claim is pointed: AI is generating diagnostic tools and drug candidates faster than the infrastructure that validates them can possibly cope with. An AI system for breast cancer screening, a retinal disease classifier for high-risk populations, a large language model accelerating drug repositioning, these are all emerging from laboratories now, already being tested in clinics, and the peer-reviewed evidence base that is supposed to justify their use is running 12 to 18 months behind. For digital health technologies that can become clinically obsolete within a year, this is not a delay. It is a structural failure.
AI diagnostic tools and drug discovery algorithms can become clinically outdated within a year of development, so evidence that lags behind by 18 months may be validating technology that has already been superseded or abandoned in practice. More critically, the tools being deployed in hospitals now may be operating on an evidence base that has never been properly verified through peer review. The gap between what AI can do and what we can formally trust it to do is widening with each new model release.
The estimates are genuinely uncertain, which is itself part of the problem. Depending on the discipline and how reproducibility is measured, studies have found failure rates ranging from around 50 to 90 percent, with psychology, biomedicine, and preclinical cancer research among the most documented cases. These figures don’t mean most science is fraudulent, but they do indicate that the peer-review and publication process is not catching the methodological problems that make results impossible to replicate.
Tools like Paperpal, Elicit, and ResearchRabbit genuinely help researchers work faster, but they all optimise the production of the same kind of output: a static, text-based manuscript. The underlying claim is still decoupled from the data that supports it, still assessed through an opaque review process, and still released as a document you can read but can’t easily verify. Speeding up the assembly line doesn’t fix what comes off it.
Open access removes the paywall but doesn’t address the deeper structural issues of speed, reproducibility, or data transparency. A freely available paper that took 18 months to publish and whose underlying data are not linked to the text is more accessible than a paywalled one, but it has the same verification problems. The cost pressures also shift rather than disappear: article processing charges of $5,000 to $11,000 create their own equity problems for researchers without institutional funding.
Rather than a finished narrative document, it would be a linked record in which the claims, the data, the analysis code, the author contributions, and the peer review comments are all permanently connected and time-stamped. Someone reading the published finding could, in principle, re-run the analysis or inspect the raw data directly from the publication itself. The concept exists in experimental form at several institutions, but has not yet displaced the traditional article as the standard output of academic science.
Chew describes the situation as pouring rocket fuel into a horse-drawn carriage. The metaphor is a bit ungentle, but it is not obviously wrong.
The problems compound. Beyond speed, there is cost. Top-tier research universities spend somewhere between $10 million and $15 million annually on journal subscriptions alone, while authors who want their work freely available often pay $5,000 to more than $11,000 per article in processing charges, creating what Chew describes as an unsustainable dual financial burden that falls hardest on researchers in lower-income countries. And then there is the matter of reproducibility, which is perhaps the deepest problem of all. Estimates of how many published research findings cannot be reproduced vary widely, but the range Chew cites runs from 50 to 90 percent depending on the discipline and the measure used. That figure is arresting almost regardless of where the true number falls.
Underlying all of this, he argues, is a structural flaw in what a published paper actually is. The traditional article is an opaque narrative summary, a story about data rather than the data itself. Claims are separated from the methods and analysis logs that would allow someone else to check them. For most of scientific history this was an acceptable compromise, because verification happened through replication. But clinical AI models are different. They are themselves black boxes, complex and largely uninterpretable systems whose trustworthiness depends entirely on the quality of the evidence they were trained on. If a clinical AI model is already opaque, Chew argues, it cannot be safely built on research that is equally unverifiable.
A chaotic ecosystem of AI tools has emerged to patch the symptoms. Research-writing assistants like Paperpal and SciSpace help authors draft manuscripts more quickly. Systematic review platforms like Elicit and Covidence accelerate literature searches. Semantic mapping tools like ResearchRabbit help researchers find gaps in a field. Major publishers have embedded AI into their own workflows too: Elsevier uses AI to match manuscripts with reviewers, Springer Nature has a prescreening system, Frontiers runs automated checks for image integrity. Chew’s view of all of this is that it is well-intentioned but beside the point. These tools optimise the creation of the traditional static manuscript. They make the horse-drawn carriage slightly faster. They do not change what the carriage is.
What would change it, in his account, is something more radical: a replacement of the static paper as the primary unit of scientific communication with what he calls an enriched dynamic research object. In this model, data, methods, analysis logs, author contributions, and peer validation records would all be permanently and structurally linked to the published claim, time-stamped and machine-readable. Verification would be built into the artifact, not delegated to a future replication attempt that may never happen. AI would serve as the core engine of a single integrated workflow, not a patchwork of disconnected tools bolted onto an obsolescent process.
The practical barriers to this are not primarily technical. The technology, Chew says, “is almost here.” Several experimental frameworks for linked, computable research objects already exist, and open science advocates have been pushing versions of this idea for years. The harder problem is institutional: journals, universities, funders, and researchers all have deep investments in the existing system, including its prestige hierarchies, its economic models, and its career incentive structures. Changing those requires something more than a clever platform.
The commentary is ultimately a call for collective will rather than a technical roadmap, and sceptics might reasonably note that calls for collective will in academic publishing have a long and not especially successful history. The reproducibility crisis has been documented for more than a decade; the access and cost problems even longer. The static paper has survived every prediction of its imminent demise.
But the arrival of clinical AI does change the stakes in a way that previous critiques perhaps did not. When AI diagnostic tools move from research papers into hospitals, the latency and opacity of the publishing system stops being an abstract frustration for academics and starts having consequences for patients. The question of whether we can trust the evidence base for these tools is, increasingly, a clinical question. As Chew puts it: “What is required now is the collective will to build, adopt, and apply it.” Whether the scientific community is ready to act on that is a different question entirely, and one the publishing system, characteristically, offers no quick answer to.
DOI / Source: https://www.jmir.org/2026/1/e96018
ScienceBlog.com has no paywalls, no sponsored content, and no agenda beyond getting the science right. Every story here is written to inform, not to impress an advertiser or push a point of view.
Good science journalism takes time — reading the papers, checking the claims, finding researchers who can put findings in context. We do that work because we think it matters.
If you find this site useful, consider supporting it with a donation. Even a few dollars a month helps keep the coverage independent and free for everyone.