The spectrogram tells the story before your ears do. On the left, a waveform dense with harmonic structure, the coloured bands of a human voice in song, each vowel a warm smear of overlapping frequencies. On the right, the same file after a voice-cloning algorithm has tried to work with it: grey static, noise, the acoustic equivalent of a shredded document. To a listener, the two audio files sound identical. To the AI, they are completely different things.
That gap, between what humans perceive and what machines interpret, is the engine of a new protective framework called My Music My Choice. Developed by researchers at Binghamton University in collaboration with the startup Cauth AI, the system works by injecting imperceptible modifications into a song’s waveform before the track goes out into the world, modifications so subtle that no listener would notice them, but calibrated to derail the cloning models that increasingly threaten musicians’ livelihoods and identities.
The problem those models have created is considerable. Modern voice conversion systems, broadly known as retrieval-based voice conversion or singing voice conversion tools, can reproduce an artist’s vocal characteristics from just a few seconds of audio. The technology is open-source, widely available, and not particularly difficult to use. It was built, largely, for entertainment: the ability to hear a song sung in a different voice is genuinely novel and fun. But it has also enabled a surge of deepfake recordings, fake collaborations, and songs misattributed to artists who had nothing to do with them, causing financial damage, reputational harm, and a kind of identity theft that copyright law has struggled to keep pace with. Major record labels launched legal action against AI music generators in 2025; Tupac Shakur’s estate threatened to sue over use of a deceased artist’s voice; a sitting celebrity was reportedly unhappy to find her vocal identity potentially copied without consent.
The conventional response has been detection, trying to identify synthetic voices after the fact. Useful, perhaps, but in Ciftci’s view you have by then already lost.
“Even though this AI technology has been developed for fun and entertainment, a lot of people are using it for nefarious purposes,” says Umur Aybars Ciftci, a research assistant professor at Binghamton University who led the work. “You can easily take someone’s voice and make them sing something that they normally don’t sing, or steal someone’s songs and make it look like it is your song to begin with.”
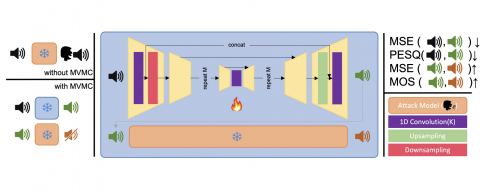
My Music My Choice is what the field calls a proactive defence, something applied before a song is released rather than after it has been cloned. The system runs the vocal track through a U-Net architecture, a type of neural network originally developed for biomedical image segmentation, operating directly on the raw waveform rather than on a spectrogram or a lossy compression of the audio. The network outputs a version of the vocal that is, by all human measures, the same recording; the changes it introduces are smaller than what a standard audio conversion process would produce. What those changes do to a voice-cloning system is rather more dramatic.
In tests on 150 tracks drawn from the MUSDB18 dataset spanning pop, rock, and world music, the protected vocals scored 0.912 on a standard intelligibility measure (a score of 1.0 would be perfect fidelity). When a cloning system tried to reproduce the protected voice, its output dropped to 0.420 on the same scale. The perceptual quality score, rated on a 4.5-point scale, held at 3.87 for the protected version; the clone scored just over 1.0. On a subjective quality measure rated out of 5, the protected file scored 3.88; the clone fell to just above 2. In other words: the real version still sounds like music, the clone sounds like something has gone badly wrong in the processing chain. And the protection carries through when protected vocals are reinserted into full songs with instrumental backing, which matters, because that is how tracks are actually released.
Getting those numbers required balancing four competing objectives simultaneously. The system has to keep the protected vocal close to the original (the reconstruction goal), ensure it sounds perceptually unchanged to human ears (the perceptual goal), maximise how far the clone’s output strays from the original (the distortion goal), and ensure the cloned output becomes semantically unintelligible, not merely noisy (the opinion goal). “Our goal is to build a model that figures out exactly which tiny modifications to introduce so that people hear no difference at all, while AI voice-cloning systems are thrown off,” says Ciftci. “In other words, we’re trying to minimize the impact on human listeners while maximizing disruption for the machines.”
There’s one thing MMMC doesn’t do, and the researchers are careful about it. The system operates as a black-box attack, meaning it does not require access to the cloning model’s internal parameters or gradients. That’s a deliberate choice: any approach that required knowing the cloning system’s architecture in advance would be brittle, outpaced the moment a new model appeared. By attacking the output quality end-to-end rather than targeting a specific component, the protection has some degree of transferability across different cloning architectures, though testing against a broader range of systems remains on the roadmap.
Similar defensive work has been done for visual content, protecting faces from GAN-based manipulation, shielding artistic styles from imitation by text-to-image models. Musical audio is a harder problem. Speech-based voice protection systems exist but fail when applied to singing, which has to survive pitch contours, vibrato, sustained notes, and the complex interaction between a vocal and the instrumental bed it sits in. “Collaborating with disruptive startups like Cauth AI provides us with a unique vantage point into the front-line challenges of the industry, essentially bridging the gap between lab-scale concepts and industrial-scale impact,” says Ciftci.
The practical workflow, if the system reaches production, would be simple enough. A musician finishing a track would run the vocal stems through the protection before mixing down the final master. The released version would be indistinguishable from what they intended to put out; the protective layer would be baked in invisibly. Whether that framing holds under adversarial pressure from increasingly sophisticated cloning models is the question that will define whether tools like MMMC become standard production infrastructure or remain one move in an ongoing back-and-forth. The researchers themselves gesture toward what might come next: ownership verification by audio steganography, multi-modal content protection standards. For now, the spectrogram on the right just shows noise. That might be enough.
DOI / Source: NeurIPS 2025 Workshop: AI for Music. Binghamton University press release via Newswise, 4-Mar-2026.
Frequently Asked Questions
Watermarking and detection-based approaches are retroactive: they can flag a synthetic voice after it has already been created and potentially distributed. My Music My Choice works before release, modifying the audio so the cloning attempt produces garbled output in the first place. Whether the two approaches will eventually be combined into a single workflow is an open question.
The modifications are embedded in the vocal waveform itself, not in the overall audio mix, and the researchers found that protection quality held when protected vocals were reinserted into complete songs. Interestingly, the instrumental backing can actually mask some of the vocal artifacts in the protected version, making the final track sound slightly cleaner to human listeners than the isolated vocal alone.
Robustness against deliberate removal attempts is flagged by the researchers as a limitation to be quantified in future work. The system currently attacks end-to-end output quality across different cloning architectures, which provides some generalisability, but it does not yet have a tested guarantee against adversarial stripping. This is likely where the arms-race dynamic becomes most important.
The idea is that this would become a pre-release production step, applied to vocal stems before the final master goes out. For the listener, the released track would sound entirely normal. The protective layer would be embedded and invisible, similar in workflow terms to loudness normalisation or limiting, just with a different purpose.
ScienceBlog.com has no paywalls, no sponsored content, and no agenda beyond getting the science right. Every story here is written to inform, not to impress an advertiser or push a point of view.
Good science journalism takes time — reading the papers, checking the claims, finding researchers who can put findings in context. We do that work because we think it matters.
If you find this site useful, consider supporting it with a donation. Even a few dollars a month helps keep the coverage independent and free for everyone.